In my last post I wrote about building Sensei — a personal AI tutor that delivers scheduled lessons to Discord using Claude. The system worked well: I could define a curriculum, schedule delivery, and get personalized content daily. But once I had content flowing, a new question came up — how good is it, actually?
The quality problem
The V1 had some issues. Lesson length was inconsistent. New lessons sometimes repeated content from earlier in the sequence because they had no awareness of what came before. Formatting varied. The content was generally good — sourced from topics in high level software engineering roles listed online — but “generally good” isn’t measurable.
I fixed the context problem by summarizing previous lessons and injecting them into the prompt for each new one. That helped with repetition. But I still had no way to quantify quality or track whether my prompt changes were making things better or worse.
Defining “good”
Designing metrics for what a good lesson looks like requires real thought. A few things that matter:
- Repetition avoidance — don’t rehash content from previous lessons
- Consistent formatting — proper markdown, code blocks, heading structure
- Reliable information — accurate coverage of the stated topic
- Good teaching — progression from intuition to examples to practice
Some of these are easy to check programmatically. Others need judgment. That split became the core design of the tool.
How sensei-eval works
I built sensei-eval as a standalone npm package so it could be reused across projects, not just Sensei. It uses a two-tier evaluation system:
Deterministic checks run instantly — verifying markdown formatting, checking content length, ensuring code blocks exist, and validating document structure. These are pure functions with no external dependencies.
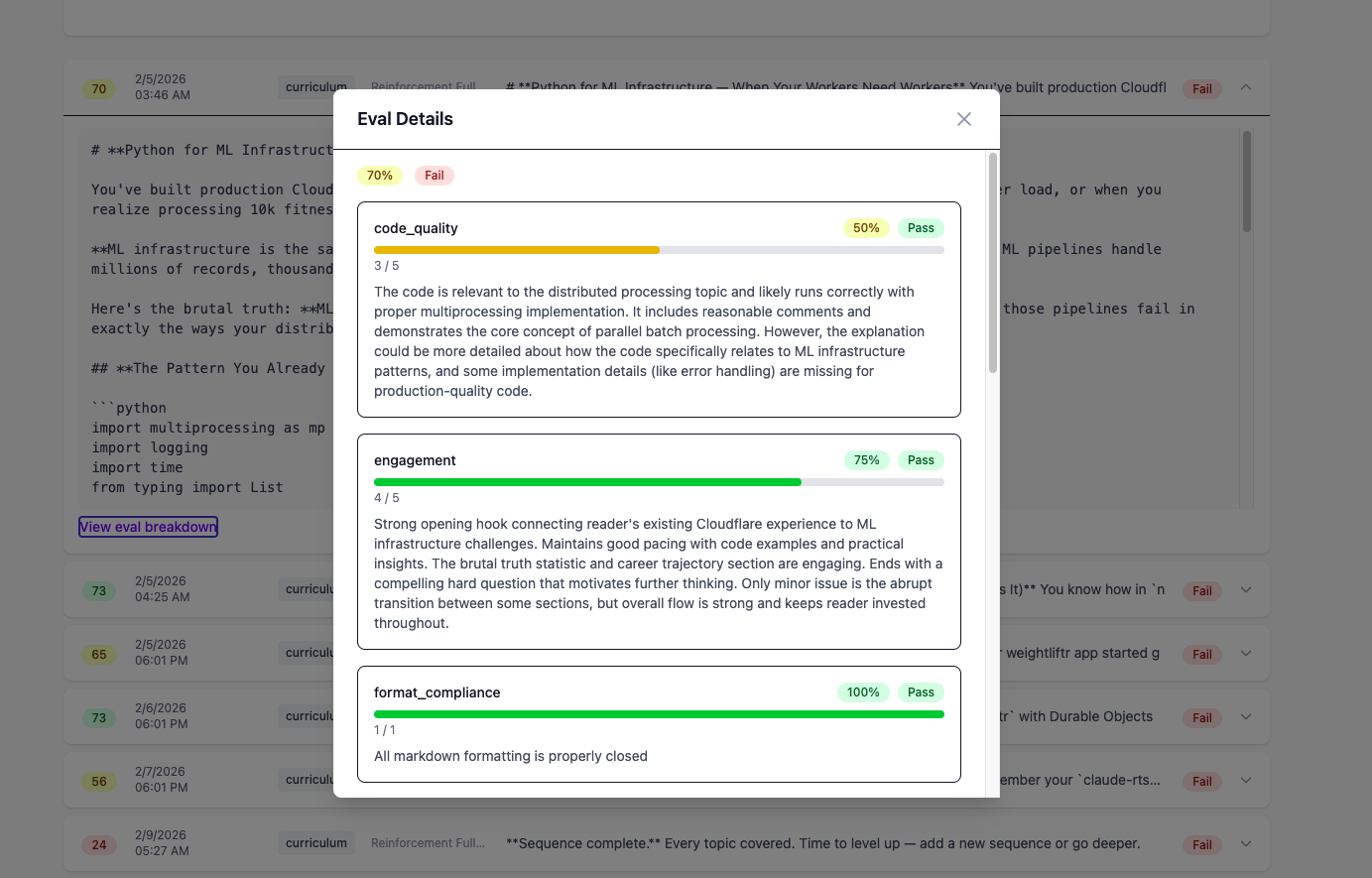
LLM-judge criteria send the content to Claude with specific rubrics. Each rubric defines a 1-5 scale for a particular quality dimension — topic accuracy, pedagogical structure, code quality, engagement, repetition avoidance. The raw scores are normalized to 0-1.
Each criterion has a weight. High-signal criteria like topic_accuracy and pedagogical_structure weight 1.5x. Structural checks like has_code_block and has_structure weight 0.5x. The overall score is a weighted average, and every criterion must individually pass its threshold for the evaluation to pass.
Using it in practice
Every time Sensei delivers a lesson, a function takes the generated content and runs it through sensei-eval. The results get stored in the database alongside the message.
When I get home each day I can check the admin UI — see the lesson that was delivered, the per-criterion scores, and decide if the numbers match my actual reading experience. Over time this builds a feedback loop: I notice which criteria consistently score low, adjust the system prompt, and watch the scores on subsequent lessons.
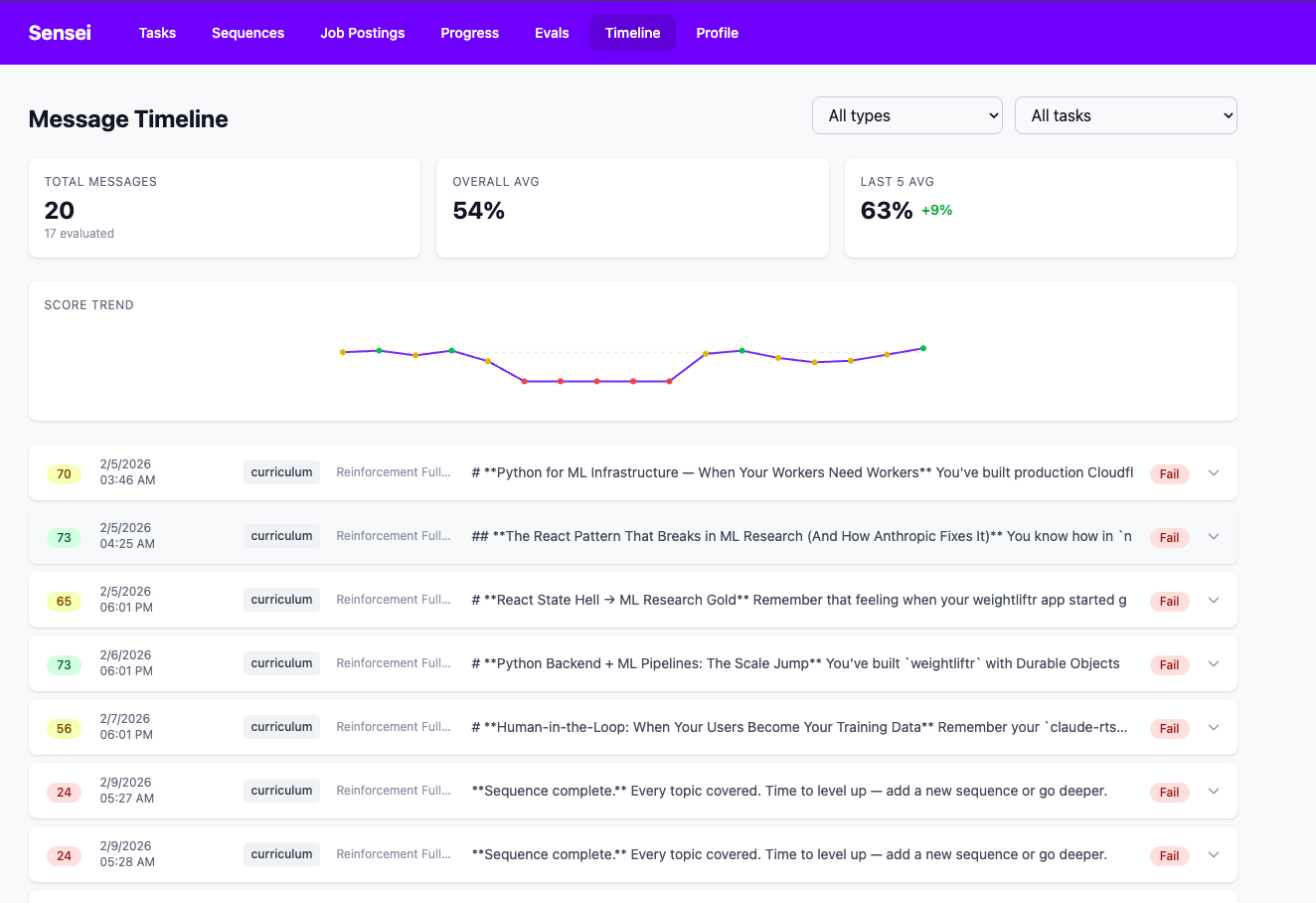
Sample output from the CLI:
PASS neural-networks-lesson (82.5%)
PASS backprop-challenge (78.3%)
FAIL review-session (61.0%)
With verbose mode, you get per-criterion breakdowns:
PASS neural-networks-lesson (82.5%)
+ format_compliance: 100.0%
+ topic_accuracy: 87.5%
+ pedagogical_structure: 81.3%
- repetition_avoidance: 62.5%
CLI and CI regression detection
Continuing to iterate, I added a CLI that lets you define prompts in a config file, generate baseline scores, and compare against them on PRs.
// sensei-eval.config.ts
import type { SenseiEvalConfig } from 'sensei-eval';
const config: SenseiEvalConfig = {
prompts: [
{
name: 'neural-networks-lesson',
content: generatedLessonMarkdown,
contentType: 'lesson',
topic: 'Neural Networks',
difficulty: 'intermediate',
},
],
};
export default config;The workflow is straightforward:
npx sensei-eval baseline # generate scores on main
npx sensei-eval compare # compare PR against baselineYou generate a baseline on main and commit it. When a PR changes a prompt, sensei-eval compare evaluates the current prompts and diffs the scores against that baseline. If anything regresses, the command exits non-zero and the PR fails.
There’s also a GitHub Action that wraps the CLI — pass your Anthropic API key and it handles setup, evaluation, and writing a markdown summary to the PR:
# .github/workflows/prompt-quality.yml
- uses: CodeJonesW/sensei-eval@v1
with:
anthropic-api-key: ${{ secrets.ANTHROPIC_API_KEY }}The key insight was using a committed baseline file rather than re-evaluating main on every PR. This cuts LLM cost in half and avoids non-determinism from comparing two separate LLM runs.
Onward
Building the eval package required understanding what makes good educational content, which is itself an exercise in learning about learning. The tool forces me to articulate what “good” looks like, and that articulation makes the prompts better, which makes the lessons better, which teaches me more.
sensei-eval is on npm. I’m using it to score content in Sensei and as a CI quality gate via the GitHub Action. If you’re building anything that generates educational content with LLMs, it might be useful to you too.